前言
Kafka 作为愈加流行的流处理平台,让人好奇它为何如此受人青睐,盛名之下无虚士,我从性能角度来探索 Kafka 的奥妙。
明确Kafka的性能阵地
首先,明确研究问题的方向。Kafka 是一个分布式的流式数据平台
它的重要功能有:
- 消息系统,提供事件流的发布与订阅
- 持久化存储,避免消费者节点故障的容错功能
- 流处理,如流的聚合、连接,具象来说是处理乱序/延迟的数据、窗口、状态等操作
在大数据需求背景下,Kafka 必然要对以上功能进行性能优化,性能的优化要点/瓶颈在于:
- 数据流的传输效率
- 生产者批量发送消息,消费者拉取消息的过程,消息的实时性、可靠性、吞吐量
- 平台级别的持久化存储方案,高容错,多节点备份
数据流的传输效率
利用操作系统的IO优化技术,脱离JVM的内存局限。
为什么从操作系统说起呢?人们每天都在使用操作系统,反而普遍忽略的操作系统的作用,让我们回想起来,操作系统的一大作用是消除硬件差异,为用户程序提供统一标准的API,由此,大部分人使用IO停留在调用系统的 read/write,后端工程师则会更多了解 NIO 的 epoll/kqueue。仅此而已了吗? 让我们看看下面优化策略:
磁盘IO的优化策略 mmap
实际上,现代的操作系统已经对磁盘IO做了复杂的优化,Linux 下有一个常见的缩写名词 vfs,即虚拟文件系统(virtual file system),它对内存与外存(磁盘)进行映射,使读写速度得到提升,比如以下且不限于:
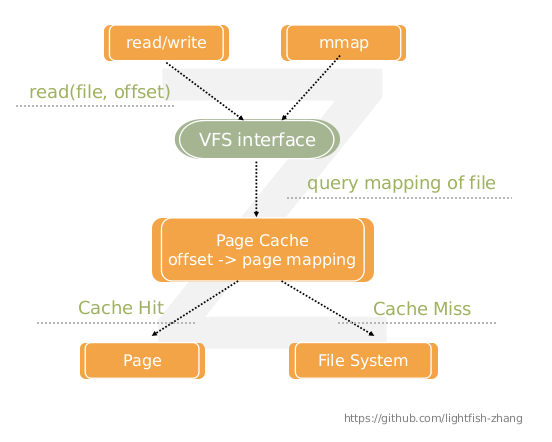
- 预读(read-ahead),提前将较大的磁盘块载入内存,用户程序读取该磁盘上数据的效率,就等同将内核的内存拷贝到用户程序分配的内存上的速度
- 后写(write-behind),一定次数的小的逻辑写操作会映射到磁盘缓存(page cache),合并为一个大的物理写操作。写入的时机一般是操作系统周期性
sync而定,用户亦可主动调用sync,(PS:在Linux用户都该知道拔U盘前执行一次sync)
以上的内存/磁盘映射的优化,这依赖于操作系统的预测策略,一般而言,往往是对磁盘的顺序访问,效率明显更高。
操作系统除了自动完成以上的过程,还提供API mmap 给用户主动映射文件到page cache,系统会将这一片page cache共享给用户程序的内存,用户程序不必提前 alloc memory,直接读取页面缓存即可访问数据。于是,在频繁访问一个大文件时,比起单纯的write,mmap是一个更好的选择,它减少了普通write过程中的用户态与内核态的上下文切换次数(反复复制缓存)。
socket IO 的优化策略 Zero-Copy
上面我们认识了磁盘缓存的优化策略,那么对于另一个被频繁使用的IO对象—— socket ,如何优化呢
先认识 Linux 2.1起引入的 sendfile 系统调用,通过 sendfile,我们可以把 page cache 的数据直接拷贝到 socket cache 中,仅仅将两者的文件描述符、数据的 offset 与 size 传参给 sendfile, DMA引擎 (Direct Memory Access,直接内存存取)会将内核缓冲区的数据拷贝到协议引擎中去,不需要经过用户态上下文,不需要用户程序准备缓存,于是用户缓存为零,这就是 Zero-Copy 技术。
#include<sys/sendfile.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
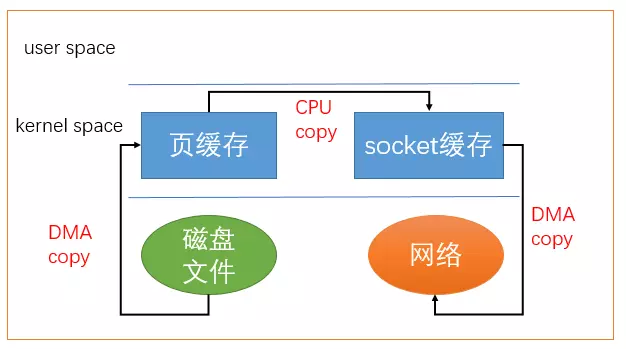
Zero-Copy 技术对 Java 程序来说无异于神兵,让缓存的大小与速度脱离了 JVM 的局限。
结合Kafka的使用场景——多个订阅者拉取消息,消息被多个不同的消费者拉取,使用 Zero-Copy 技术,先调用 mmap 读取磁盘数据到一份 page cache,再多次调用 sendfile 将一份 page cache 复制到不同的 socket cache,整个复制过程在系统内核态中完成,极致的利用了操作系统的性能,瓶颈近乎限于硬件条件(磁盘读写、网络速度)。
消息的实时性、可靠性、吞吐量
制衡之道
从人类实践活动,我们有一个经验是:在一项事情中需要实现多个目标时,往往得到在多个指标相互制衡的结果。
- 以时间换空间——实时性与吞吐量
Kafka为了解决网络请求过多的问题,生产者会合并多条消息再提交,降低网络IO的频繁,以牺牲一点延迟换取更高的吞吐量。
在实践中,我们可以为生产者客户端配置这个过程的参数,例如:设置消息大小上限为64字节,延迟时间为100毫秒,它的效果是:100毫秒内消息大小达到64字节就要立即发送,如果在100毫秒没有达到64字节,但是100毫秒时间到了,也要发送缓存中的消息。
分而治之
大数据场景下,分布式的架构设计是必然
之前分析了单机环境的策略(操作系统、通信IO),然后,在水平拓展上,Kafka有什么性能优化策略呢?
做一个分布式的消息系统,需要考虑什么呢?
如何利用分布式、多节点的优势,增强消息系统的吞吐量、容灾能力、灵活扩容的能力…
让我们将思路抽象化,消息是流动的水,单机下是一条水管,多节点下是一片自来水网络,为了使消息的流动更加稳健,我们得保证在消息流动的每一个环节都有所保障
先罗列消息流动的每一个环节
- 消息的状态,在大多数消息队列应用中,通常有三个等级:
- 生产者发布消息后不管是否被消费者收到
- 生产者发布消息后必须有一个以上的消费者收到
- 生产者发布消息后确保有且只有一个消费者收到
- 消息的缓存
- 流量削峰,在单位时间内,消费者处理流量低于生产者发布流量时,消息系统需要冗余消息
- 消费者处理消息的事务出错,或者消费者收到消息后还未处理时出故障,那么,消息需要再次处理
- 消息的顺序
- 具体业务场景对消息的顺序有要求,需要严格按照先后顺序处理消息,要保证,消费者收到时序性的消息
Kafka 如何应对这些环节呢?
Kafka 规则一,消息存储在两个维度上,虚拟上的分区(partition) 与 物理上的节点(broker),两者是多对一关系
Kafka 规则二,一个 Topic 的一个分区同一时间最多只有一个消费者线程拉取消息
Kafka 规则三,维护一个分区上消息缓存的消费者拉取进度
在水平拓展上,Kafka将一个 Topic 下从生产者收集到的消息存放到多个分区(partition)上,分区数大于等于Kafka节点数(brokers),每一个分区最多分配一个消费者
-
对于消息的缓存容量、流量分化的问题,Kafka在zookeeper的协同下,可以灵活拓展节点(brokers)
- 对于消息的状态问题,Kafka维护一个分区上的 offset 值,保存消息的消费进度,而这个进度需要由消费者提交
- 若消费者拉取某一个分区的消息,一直不提交最新的 offset 值,那么分区上的 offset 一直落后于消息实际拉取的进度,当分区与消费者的关联重新分配时,分区从上一次开始的地方重新把消息再发送一遍
- 若消费者拉取一条消息后,正常处理后,提交offset到分区,一直如此,到某一条消息的处理过程中,消费者意外发生故障,Kafka可以识别到消费者的通信连接中断,会触发分区与消费者关联的 rebalance
- 对于消息的时序问题,每一个分区最多分配一个消费者,通过维护消费进度,就可以保证同一个分区下的消息的时序性,由此:
- 在生产者发布对某一个对象具有时序性的消息时,可以为该消息标记上该对象的id,Kafka会通过该对象id的哈希值,分配消息到某一个符合哈希值的分区,由此,某一个对象的时序性消息即存放在一个分区内,由一个消费者拉取该分区的消息,可以确保消息按时序被消费者收到
- 上面场景要求在分区没有重新分配(rebalance)下才生效,若是broker节点拓展或故障,会触发分区的重新分配,另一方面,消费者节点拓展或故障,都会触发分区与消费者关联的重新分配
直观来看,分区(partition)、消费者(consumer)会发生一下几种情况的 rebalance
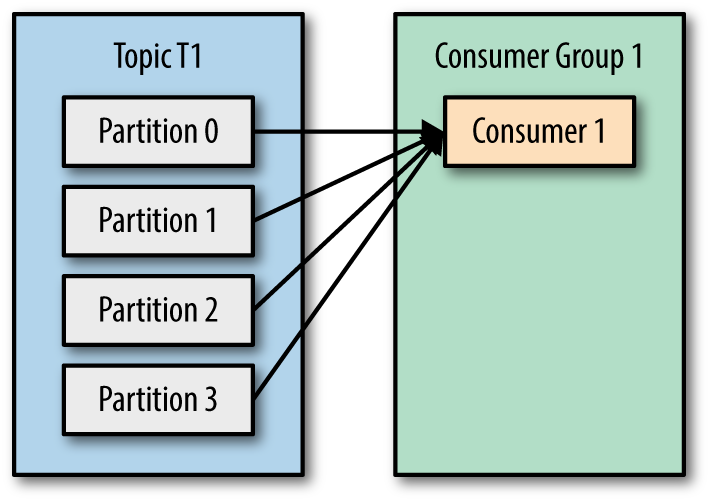
一开始有四个分区,一个消费者,四个分区的消息都需要被拉取,只好关联同一个消费者
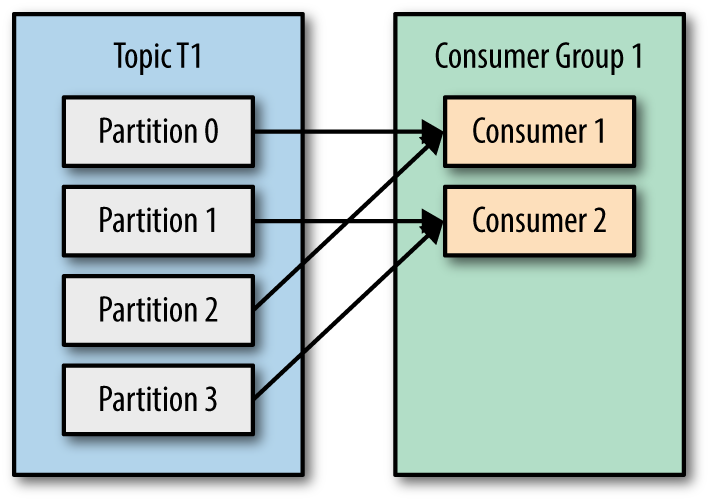
消费者有两个了,可以均衡分配
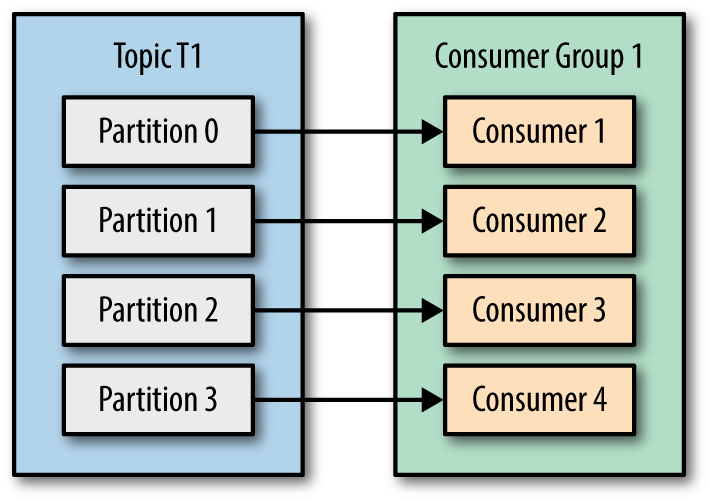
消费者四个了,更好了
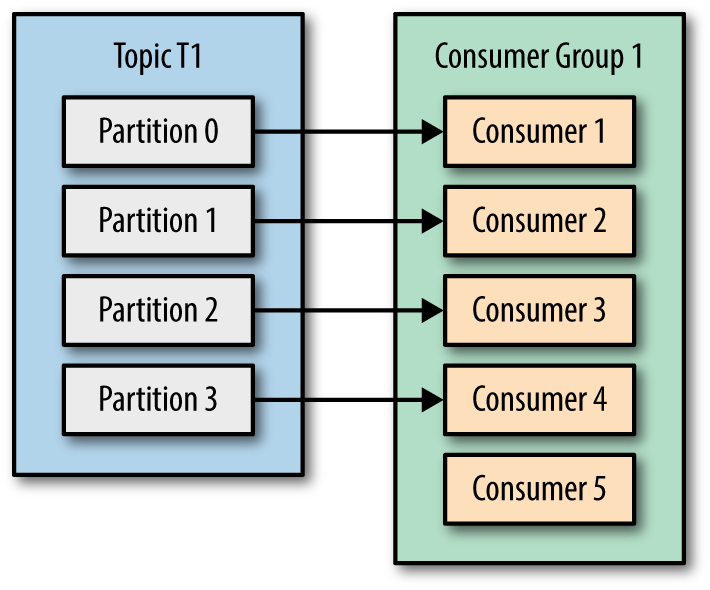
消费者五个,为了保存消息的时序性,维护一个offset值,一个分区最多只能关联一个消费者,所以这里多出一个消费者空闲了
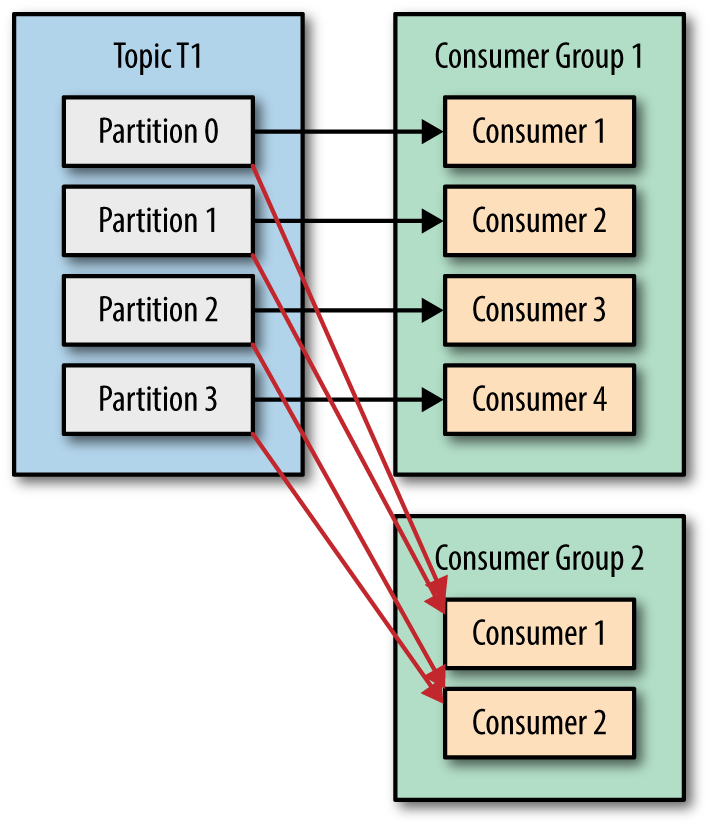
由于业务要求,消费者有两个分组了,消息的时序性是只对一个分区、一个消费者分组生效的,这里一个分区可以关联多个相互不同分组的消费者,维护多个 offset
未雨绸缪
除了水平拓展的分区,还要对总分区进行多个备份(Replicas),对一个分区设置一个 leader 多个 follower,由一个 leader 处理该分区的事务,follower 需要处于 ISR 状态(In Sync Replicas),一旦 leader 故障,通过在备份最新的 follower 中产生新的 leader
总结
- IO密集、大文件的操作,可以在操作系统层次上优化,善用
mmap,sendfile - 重复操作密集时,可以“批量”处理,以时间换空间,获得更大的吞吐量
- 分布式有一个广泛使用的设计,从两个维度进行水平拓展,虚拟分区与物理节点