前言
本文梳理了音视频编程开发者需要了解的基本概念,当然,有的人一开始看着干巴巴的理论,感到困乏,却是一个喜欢动手实践的开发者,那么先实践 ffmpeg的C语言编程入门,然后再来看理论篇更好了。
音频的基本概念
音频技术是为了采样、存储、播放”声学现象”而存在的,详细一点,是模拟信号与数字信号转换;在人耳可听的时域与频域的范围内,进行压缩、转码,在数据大小与音质的取舍中存储音频文件;播放时解读文件的音频参数,进行转码。
声学的物理知识
声音是有物体振动而产生的,是一种压力波。
声音的振动会引起空气有节奏的振动,是周围的空气发生疏密变化,形成疏密相间的纵波
通过上一句话,容易理解声波三要素:
- 频率,音阶的高低,频率越高,波长越短,而低频声音的波长较长,更容易绕过阻碍物。
- 振幅,响度,使用分贝描述响度的大小,
- 波形,音色
人耳的生物知识
回声的区分:两道声音传入人耳的时差小于 80 毫秒,人耳便无法区分这两道声音。
人耳可接收的频率范围:20Hz~20kHz
声音的数字化
数字音频的三个要素: 采样、量化、编码
- 采样,在时间轴上对信号进行数字化,根据采样定理(奈奎斯特定理),按比声音最高频率高两倍以上的频率对声音进行采样(AD转换),根据人耳可听频率,高质量的采样频率为 44.1kHz,即一秒采样44100次
- 量化,在幅度轴上对信号进行数字化,例如使用 short (16 bit) 存储空间表示一个声音采样,共有 2^16 个可能取值,于是模拟的音频信号在幅度上分为了 65536 层
- 编码,按照一定的格式记录采样和量化后的数字数据,比如顺序存储,压缩存储等
音频文件的原始格式,PCM, WAV
PCM + WAV header (44 bit) = WAV
PCM 全称 Pulse Code Modulation,脉冲编码调制,是音频的裸数据,PCM 文件缺少描述参数,一般需要 WAV header 来描述,如:量化格式(sampleFormat)、采样率(sampleRate)、声道数(channel)。

描述音频文件的大小、质量
- 比特率,对于声音格式,一个常见的描述大小的概念是,数据比特率,描述一秒时间内的比特数目,可以作为衡量音频质量的依据。
- 采样格式,比如用16 bit,即 4 字节来描述一个采样,存储空间越大,声音在频域上描述越精细。
- 采样率,比如 48kHz,采样率越大,声音在时域上描述越精细。
计算比特率的公式: 采样率 × 采样格式 × 声道数 = 比特率
声音的大小单位——分贝
什么是分贝,为什么使用分贝作单位?
若以声压值来表示声音大小,变化范围太大,可以达到六个数量级以上,另外,人耳对声音信号的强弱刺激的反应不是线性的,而是呈对数比例关系,于是采用分贝的概念:
分贝是指两个物理量之比除以 10 为底的对数并乘以 10,中文描述有点绕,看简洁的公式
N = 10 * lg(A1/A0)
分贝符号:dB, 它是无量纲的,式中 A0 是基准量,A1是”被量度”量
音频的编码
CD 音质的格式是 WAV,完整地存储采样数据。但是存储空间较大,计算一下,CD的音质参数:量化格式16 bit,采样率 44100,声道数 2,计算一秒的比特数:
44100 * 16 * 2 = 1378.125 kbps (千比特每秒) = 176400 字节每秒
一分钟的 CD 音质的存储空间约为 10.09 MB。存储空间太大,不适合在 4G 以下的网络中在线播放音频。
在实际应用中,需要对数据进行压缩,有效的压缩方法是从两个维度上进行压缩,分别是频域与时域。
提供给人类播放的音频,只需保存人耳听觉范围内的信号,于是音频压缩编码的原理实际上是压缩掉冗余信号,冗余信号包括人耳听觉范围之外的音频信号以及被掩蔽掉的音频信号等,被掩蔽掉的音频信号主要是因为人耳的掩蔽效应,主要表现为频域掩蔽效应与时域掩蔽效应,无论是时域上还是频域上,被掩蔽掉的声音信号都被认为是冗余信息,不进行编码处理。
介绍常见的音频格式:
- MP3,具有不错的压缩比,MP3其中一种实现编码格式 LAME 是中高码率的,听感接近源 WAV 文件。MP3适用于在高比特率下有兼容要求的音乐欣赏。
- ACC,新一代音频有损压缩技术,在小于 128 Kbit/s的码率下表现优异,多用于视频中音频轨的编码。
- Ogg,开源免费,在各种码率下都有比较优秀的表现,表现优于 MP3,缺点是兼容性不够好,不支持流媒体特性,适用于语音聊天的音频消息场景。
视频的基本概念
表示方式
常见两种表示方式为: RGB, YUV
RGB 概念
RGB的概念,很多人都了解,三种原色来描述一个像素点,还有 RGBA 格式,A 是透明度。
像素的取值范围有几种:
- 浮点数,取值范围 0.0 ~ 1.0,例如 OpenGL ES
- 整数,子像素的取值范围 0~255,或 00 ~ FF, 这是计算机上的 8 bit, RGBA 四个子像素即占用 32 bit,即 4 个字节,这是 RGBA_8888,也有特别的表示方法,比如安卓平台上的 RGB_565,16 bit 表示一个像素,R=5 bit, G=6 bit, B=5 bit
一张图片的裸数据是 bitmap,内存很大,也浪费空间,于是有压缩算法:
JPEG 是静态图像压缩标准,有良好的压缩性能,然而,对于视频来说还不够,视频还需要在时域上进行压缩,后面讲到。
YUV 概念
如果你未理解过 YUV 概念,来看这一张熟悉的图片:

90年代彩色电视或黑白电视,测试画面使用的图片,图片的色块直接地反映了 YUV 的色彩空间,再来看下一张端口图:
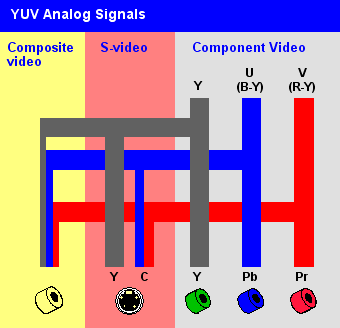
以上端口中,老式的黑白电视使用 Y C 端口,彩色电视采用 YUV 端口,以前在家接过电视盒、DVD端口的童鞋是不是很熟悉。其中 Y 代表明亮度/灰阶值 (Luma);U 和 V 代表色度(chroma),指定像素的颜色。
概括而言,YUV 主要应用于优化彩色视频信号的传输,使其向后兼容老式黑白电视。
与直观的 RGB 不同,YUV 的表示方式是差分的:
- Y 亮度,是 RGB 信号的特定部分叠加到一起的值
- U V 色度,分别是色调 Cr 与饱和度 Cb,Cr 表示 RGB 红色部分与亮度值的差异,Cb表示 RGB 蓝色部分与亮度值的差异
看下一张图片反映 YUV 与 RGB 的差异

YUV 最常见的采样格式是 4:2:0,其中 0 不代表其中一个输入为0,而是交错的 4:2:0 与 4:0:2,左右两列的色度是共享的,如下图片
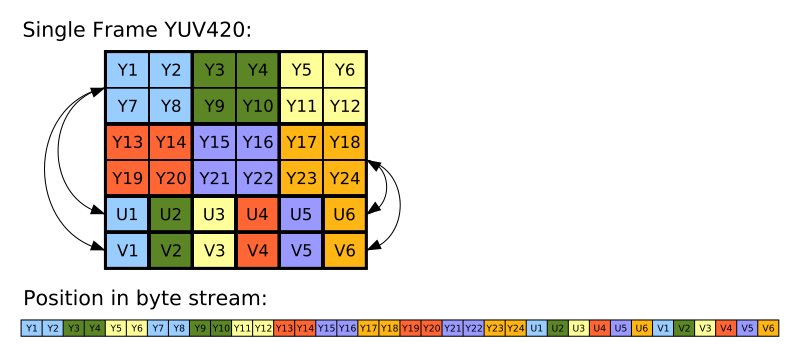
不考虑时域压缩,YUV的一帧图片比RGB的一帧图片的比特量化要大,比如 RGB 用 8 bit 表示一个像素,YUV 需要用 12 bit 表示一个像素。
了解 YUV 的概念,对于音视频编程中的客户端开发,是必要的。在IOS或安卓,摄像头采集到的裸数据格式是 YUV,然后需要调用相关API使其转换成 RGB 格式,详细暂且打住。
视频编码
音视频的编码通常是去除冗余信息,从而实现数据量的压缩。对于视频,可以从空间与时间维度上进行压缩,而且,视频数据有极强的相关性,有着大量的冗余信息。
从时间维度上去除冗余信息的方法:
- 运动补偿,通过先前的局部图像来预测、补偿当前的局部图像
- 运动表示,不同区域的图像需要使用不同的运动矢量来描述运动信息
- 运动估计,从视频序列中抽取运动信息的一整套技术
从空间维度上,运用帧内编码技术,例如,静态图像编码标准 JPEG,在视频上,ISO 制定了 Motion JPEG,即 MPEG,MPEG算法是适用于动态视频的压缩算法,除了对单幅图像进行编码外,还利用图像序列中相关原则去除冗余,大大提高压缩比。MPEG版本一直在不断更新,如:Mpeg1(用于VCD),Mpeg2(用于DVD),Mpeg4 AVC(流媒体的主力算法)
独立于 ISO 制定的 MPEG 视频压缩标准,ITU-T制定了 H.261~H.264一系列视频标准,其中 H.264吸取了众多标准的经验,采取简约设计,比起 Mpeg4更容易推广。
H.264使用了新的压缩技术,例如:多参考帧,多块类型,整数变换,帧内预测等,使用了更精细的分像素运动矢量(1/4,1/8)和新一代的环路滤波器。
编码的细节概念
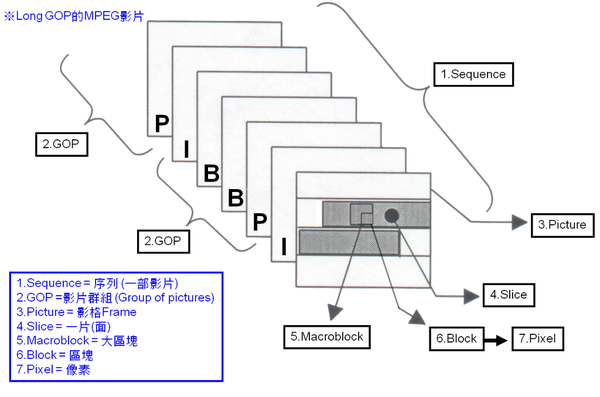
IPB 帧,是最常见的帧间编码技术类型,在GOP(Group Of Pictures)中有以下三种帧:
- I 帧,intra picture,帧内编码帧,I帧通常是每个 GOP 的第一个帧,进过适度压缩,作为随机访问的参考点,可以当做静态图像。I帧压缩可以去掉视频的空间冗余信息。
- P 帧,predictive picture,前向预测编码帧,通过将图像序列中前面已编码帧的时间冗余信息充分去除压缩传播数量的编码图像,简称预测帧。
- B 帧,bi-directional interpolated prediction frame,双向预测内插编码帧,与P帧不同的是,它同时参考图像序列前面与后面的已编码帧的时间冗余信息。
gop_size,代表两个 I 帧之间的帧数目。理论上,在存储空间固定的条件下,gop_size越大,画面质量越好,因为可以留下更多的空间存储画质更高的 I 帧。
压缩比,一般而言,I帧的压缩率是 7 (与 JPG 差不多),P帧是20,B帧是50
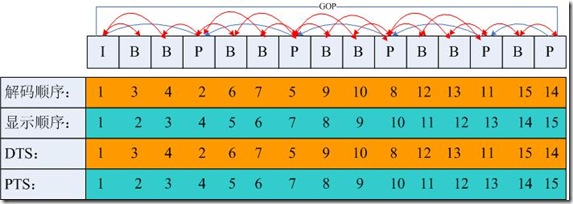
PTS 与 DTS
- DTS, decode timestamp,数据压缩包 packet 的解码时间
- PTS, presentation timestamp,视频帧 frame 的展示时间
一般来说,如果视频的各帧编码是按输入顺序依次进行的,那么解码时间与显示时间应该一致,然而事实上,大多数编解码标准(如H.264),编码顺序与显示顺序并不一致,于是需要 PTS 与 DTS 两种时间戳。
Tip: 在 FFmpeg 工具中,AVPacket结构体是描述解码前或编码后的压缩数据,AVFrame是描述视频的一帧图像,而 DTS 是 AVPacket 结构体的一个成员属性,PTS 是 AVFrame 的一个成员属性。另外,FFmpeg 中还有一个属性,基准时间 time_base ,即每 1 pts 的时间间隔,单位秒
Reference
本文的文字摘抄于《音视频开发进阶指南》,即是我阅读后将知识内化的再输出
图片均来自互联网